
My research centers on enabling human-like behavior in robots by bridging the gap between learning and physical design. A central theme in my work is the integration of human-inspired priors (inductive biases that reflect how humans perceive, plan, and act) into robot learning systems. These priors help robots generalize better, learn from fewer demonstrations, and adapt to complex, unstructured environments.
# Human-inspired priors in action: InterACT
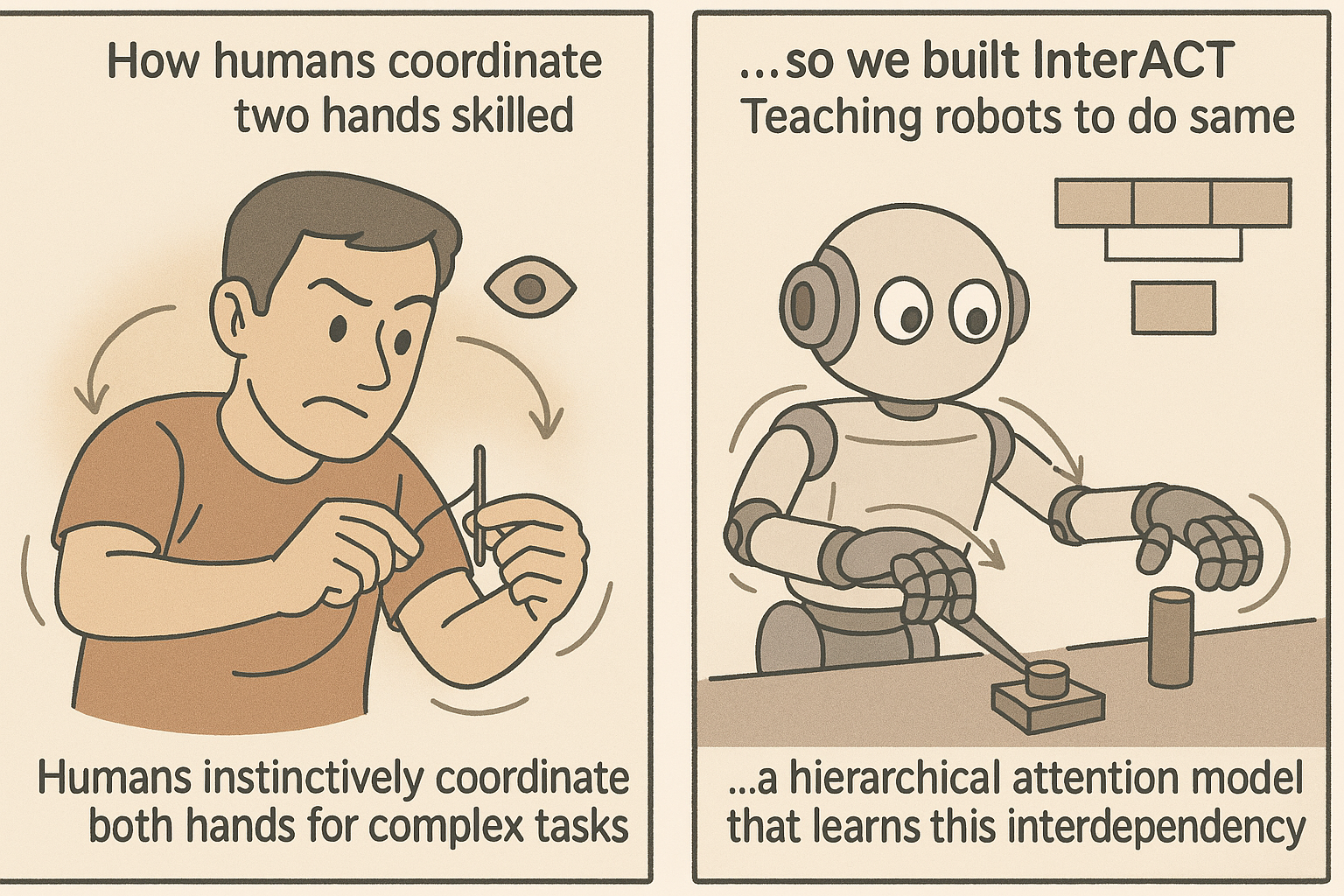
In our work on InterACT (Inter-dependency Aware Action Chunking with Transformers) 1, we developed a hierarchical attention framework tailored for bimanual manipulation, inspired by how humans coordinate both hands during skilled tasks.
Key innovations include:
- Segment-wise and cross-segment attention to model intra- and inter-arm dependencies
- A dual-decoder architecture where each arm receives separate, but synchronized control
- Use of CLS tokens and a synchronization block to facilitate smooth coordination
By reflecting the compositional and interdependent nature of human motion, InterACT achieved strong results across a range of real-world tasks (plug insertion, cap unscrewing etc) demonstrating superior coordination and precision.
# Is Active Vision is what robots need?
Another interesting capability found in humans is Active Vision: the natural ability to adjust one’s viewpoint for better perception. . We humans are always moving. Shifting our heads, eyes, and even bodies to get a better look at small or occluded objects. This dynamic viewpoint control allows us to handle intricate tasks like threading a needle or inserting a key into a lock with ease. However, most robot learning setups use static or task-agnostic cameras, which struggle in occluded or fine-detail scenarios. Even eye-in-hand cameras attached to the end-effectors can be limited because their viewpoint is tightly coupled with the robot’s manipulation motion. When precision matters, the robot may not “see” what it needs to.
To address this, we introduced AV-ALOHA (Active Vision ALOHA) 2, a bimanual teleoperation system with a dedicated 7-DoF camera arm that functions solely for active vision. During demonstrations, a human operator wears a VR headset to control the AV arm using head and body movements, dynamically adjusting the camera perspective in real time. Just like we do in real life.
This setup allows us to collect immersive, first-person demonstrations with ideal viewpoints for each stage of the task. When learning from this data, robots trained with active vision showed significantly better performance, particularly in tasks involving:
- Occlusions (e.g., Hidden Pick task with a towel-covered object)
- Small object precision (e.g., Thread Needle task)
- Tight alignment (e.g., Occluded Insertion where the hole is under a container)
Our experiments showed that dynamic viewpoint control significantly improves imitation learning in tasks where occlusion, small objects, or precise alignment are prominent.
# Moving Forward
While AV-ALOHA 2 laid the groundwork for exploring camera control in imitation learning, it is important to acknowledge that the system is not truly “active vision” in the learning sense as it relies on human demonstrations for camera movement and does not autonomously optimize viewpoint during deployment. It serves as a platform to study the effects of viewpoint variation, but not yet a fully embodied agent that reasons about where and how to look.
Notable works such as Q-Attention 3 and Observe Then Act 4 take steps toward decoupling perception and control in a learning-based manner. Rather than entangling camera movement with manipulation, these approaches treat viewpoint selection as its own decision process, enabling agents to reason explicitly about where to look before deciding how to act.

Beyond active vision, there remain numerous human-inspired priors yet to be fully leveraged in robot learning that are not limited to:
-
Visual attention and human gaze: Humans instinctively focus their attention on task-relevant regions. This selective visual processing, often reflected in eye-tracking studies, offers a valuable prior for training models to attend to meaningful areas in a scene under visual clutter or partial observability.
-
Hierarchical control and limb coordination: From gross motor planning down to fine finger articulation, humans organize motion hierarchically. High-level goals drive mid-level subgoals, which translate into low-level control of limbs and fingers. Learning architectures that mirror this layered structure, such as through hierarchical policies can better generalize across tasks and improve dexterity.
While I have not yet detailed each of my on-going projects, they continue to build on this foundation by integrating human-inspired priors more systematically into both the perception and control pipelines.
Across these efforts, my goal is to develop agents that don’t just perform tasks, but perceive with intention, move with purpose, and adapt with structure. Much like how humans do.
Stay tuned for updates! And if your research is closely related, I’d love to connect! Whether it’s to exchange ideas, explore collaboration opportunities, or just chat about robots.
References
-
Lee, A., Chuang, I., Chen, L. Y., & Soltani, I. (2024). InterACT: Inter-dependency Aware Action Chunking with Hierarchical Attention Transformers for Bimanual Manipulation. arXiv preprint arXiv:2409.07914. ↩
-
Chuang, I., Lee, A., Gao, D., Naddaf-Sh, M., & Soltani, I. (2024). Active vision might be all you need: Exploring active vision in bimanual robotic manipulation. arXiv preprint arXiv:2409.17435. ↩ ↩2
-
James, S., & Davison, A. J. (2022). Q-attention: Enabling efficient learning for vision-based robotic manipulation. IEEE Robotics and Automation Letters, 7(2), 1612-1619. ↩
-
Wang, G., Li, H., Zhang, S., Guo, D., Liu, Y., & Liu, H. (2025). Observe Then Act: Asynchronous Active Vision-Action Model for Robotic Manipulation. IEEE Robotics and Automation Letters. ↩